
Ontologien im Asset Management: Überholt, unterschätzt oder der Schlüssel zur KI-integrierten Datenarchitektur?
In einer Zeit, in der Datenvolumen explodieren und Künstliche Intelligenz zunehmend Entscheidungsprozesse im Asset Management mitprägt, rücken strukturierte Begriffswelten – sogenannte Ontologien – wieder ins Zentrum der Diskussion. Lange galten sie als sperrig, teuer und schwer zu pflegen. Doch nun stellt sich die Frage: Sind Ontologien angesichts dynamischer KI-Systeme obsolet geworden – oder bilden sie weiterhin das unverzichtbare Fundament für semantische Interoperabilität, regulatorische Nachvollziehbarkeit und maschinelle Interpretation?
Disclaimer
Dieser Artikel dient ausschließlich zu Informationszwecken und stellt keine rechtliche, steuerliche oder investmentbezogene Beratung dar.
1. Warum Ontologien wieder auf der Agenda stehen
Viele Asset Manager erkennen, dass reine Datenhaltung ohne semantische Strukturierung an Grenzen stößt – etwa bei ESG-Reportings, Look-through-Anforderungen oder der Harmonisierung von Produkt- und Risikodaten über mehrere Systeme hinweg. Ontologien versprechen Ordnung: Sie schaffen eindeutige Begriffe, Relationen und Klassifikationen, die sowohl von Menschen als auch von Maschinen interpretiert werden können. Sie ermöglichen semantische Interoperabilität – also die Fähigkeit verschiedener Systeme (z.B. IBOR, ABOR, Reporting-Tools), ein gemeinsames, konsistentes Verständnis von Begriffen wie „Fonds“, „Anlageklasse“, „Risiko“ oder „Nachhaltigkeitsfaktor“ zu haben.
Mit dem Vormarsch von Künstlicher Intelligenz (KI) stellt sich jedoch die Frage: Wozu noch strukturieren, wenn man Daten auch probabilistisch „verstehen“ kann?
2. Definition und Nutzen klassischer Ontologien im Asset Management
Ontologien sind strukturierte Wissensmodelle, die Konzepte (z.B. „Alternative Investment Fund“, „Green Bond“) und deren Beziehungen (z.B. „gehört zu“, „ist Unterklasse von“, „investiert in“) formal beschreiben. In der Praxis bedeutet dies:
- Einheitliche Begriffswelten: Schaffung eines konsistenten Vokabulars für interne Kommunikation, regulatorische Reports und Datenfeeds, das Mehrdeutigkeiten reduziert.
- Wiederverwendbarkeit von Modellen: Entwicklung strukturierter Datenmodelle für Fonds, Assetklassen oder Risikofaktoren, die über verschiedene Jurisdiktionen und Produkte hinweg wiederverwendet werden können.
- Systeminteroperabilität: Ermöglichung semantischer Mapping-Schichten zwischen verschiedenen Systemen (z.B. ABOR-, IBOR- und ESG-Systeme), die sicherstellen, dass Daten aus unterschiedlichen Quellen konsistent interpretiert werden.
3. Relevante Einsatzbereiche: Von Produktstruktur bis ESG-Reporting
In der Praxis kommen Ontologien u. a. in folgenden Bereichen des Asset Managements zum Einsatz:
- Instrumentenklassifikation: Eindeutige Klassifizierung von Finanzinstrumenten und Produkten gemäß regulatorischer Vorgaben (z.B. MiFID, PRIIPs, SFDR).
- Stammdatenmanagement (MDM): Schaffung einer konsistenten Taxonomie für Stammdaten (Fonds, Investoren, Assets), um eine Single Source of Truth zu gewährleisten.
- Fee Mapping: Eindeutige Zuordnung verschiedener Gebührenarten (Management Fee, Carried Interest, Transaktionskosten) zu regulatorischen oder internen Kostenkategorien.
- Look-through-Strukturen: Semantische Verlinkung und Zerlegung von Fondsstrukturen in ihre Sub-Assets, um komplexe Look-through-Anforderungen zu erfüllen.
- ESG-Tagging: Systematische Einordnung von Investments gemäß regulatorischer Vorgaben (z.B. EU-Taxonomie) oder interner Nachhaltigkeitskriterien (z.B. PAI-Logik).
- Produktdatenharmonisierung: Strukturierte Abbildung von Produktbäumen, Anteilsklassen, Gebühren- und Risikostrukturen über das gesamte Produktportfolio hinweg.
4. Herausforderungen bei Aufbau und Pflege von Ontologien
Trotz ihres Nutzens sind Ontologien in der Praxis oft ressourcenintensiv:
- Kosten: Hoher Initialaufwand für die Modellierung der Ontologie, die Implementierung von Tools und die Schulung von Personal (Fachexperten, IT-Architekten).
- Pflegeaufwand: Ständiger Abgleich der Ontologie mit neuen Produkten, Marktbedingungen und insbesondere regulatorischen Änderungen (z.B. jährliche Updates der EU-Taxonomie).
- Änderungsmanagement: Notwendigkeit von Versionskontrolle, Gültigkeitszeiträumen und Impact-Analysen bei Änderungen an der Ontologie, um die Konsistenz über alle Systeme hinweg zu gewährleisten.
- Komplexität: In dynamischen Private Market Architekturen kann ein zu starres ontologisches Modell hinderlich wirken, wenn es nicht flexibel genug ist, um neue Strukturen oder Produkte abzubilden.
5. KI statt Ontologie? – Potenziale moderner Sprach- und Klassifikationsmodelle
Künstliche Intelligenz – insbesondere Large Language Models (LLMs) und Embedding-Technologien – können viele Aufgaben semantischer Klassifikation auch ohne eine formale Ontologie erfüllen:
- Automatisierte ESG-Zuordnung: KI kann auf Basis von unstrukturierten Textdaten (z.B. aus Nachhaltigkeitsberichten, Pressemitteilungen) ESG-Themen identifizieren und Investments klassifizieren, ohne explizite Ontologie.
- Klassifikation von Fondsstrukturen: Machine Learning kann anhand historischer Trainingsdaten Muster in Vertragsdokumenten erkennen und Fondsstrukturen automatisch klassifizieren.
- Anomalieerkennung: KI kann Abweichungen und Lücken in Datenströmen identifizieren.
Herausforderungen von KI-only Ansätzen:
- Mangelnde Erklärbarkeit: KI-Modelle arbeiten probabilistisch und ihre Ergebnisse sind oft schwer nachzuvollziehen („Black Box“-Problem). Dies ist bei regulatorischer Verwendung, bei der Nachvollziehbarkeit erforderlich ist, problematisch.
- Abhängigkeit von Trainingsdaten: KI ist stark von der Qualität und Quantität der Trainingsdaten abhängig. Ontologien hingegen liefern konsistente, regelbasierte Logik.
- Risiko von „Halluzinationen“: KI kann inkonsistente oder falsche Informationen generieren.
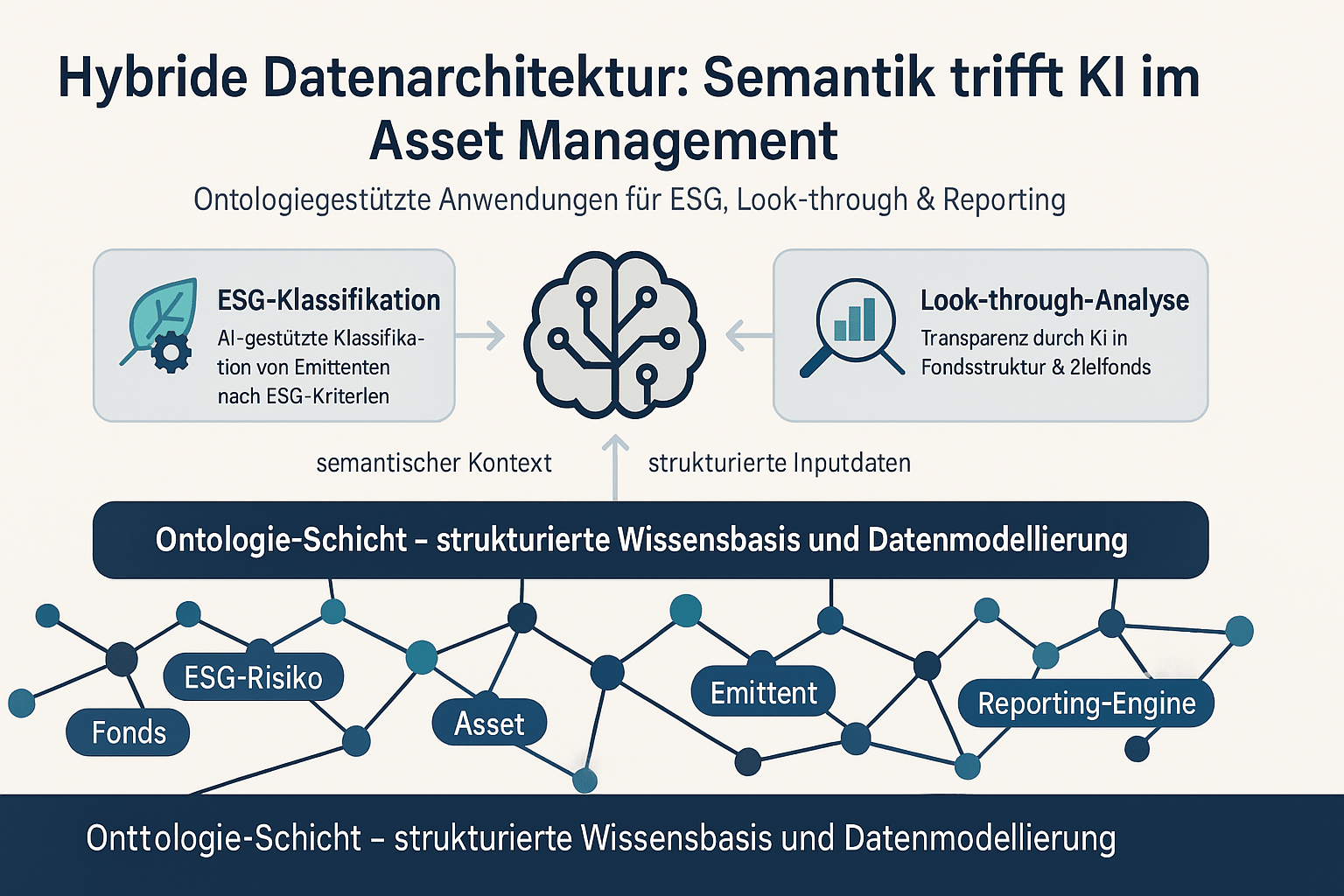
6. Gemeinsames Potenzial: Ontologie als semantisches Rückgrat für KI
Statt Ontologie und KI als Gegensätze zu sehen, liegt die Zukunft in hybriden Architekturen. Dabei dient die Ontologie als stabiler semantischer Unterbau („semantisches Rückgrat“), während KI dynamische Interpretation, Kontextualisierung und Vorverarbeitung übernimmt. Ontologien können KI helfen, inkonsistente oder falsche Ergebnisse zu vermeiden, indem sie einen regelbasierten Rahmen für die KI-generierten Daten liefern. Beispiele:
- Wissensgraphen (Knowledge Graphs): Verknüpfen KI-generierte Entitäten (z.B. identifizierte Unternehmen, Personen, ESG-Themen) mit den formalen Konzepten und Relationen einer Ontologie.
- Prompt-Steuerung: LLMs nutzen das definierte Vokabular der Ontologie zur besseren Steuerung von Anfragen (Prompts) und zur Generierung konsistenter, strukturierter Antworten.
- Strukturierte Embeddings: Embeddings (numerische Repräsentationen von Wörtern oder Konzepten) werden strukturiert durch Ontologie-basierte Clusterlogik, was die Genauigkeit von Klassifikationsmodellen erhöht.
7. Praktisches Beispiel: ESG-Klassifikation eines Real Assets
Ein Infrastrukturprojekt (z.B. Solarpark in Spanien) wird analysiert:
- Ontologie-only: Die ESG-Kategorisierung erfolgt auf Basis formaler, manuell erfasster Merkmale (z.B. Projektart „Solar“, Standortdaten, technische Spezifikationen) und deren Abgleich mit den Regeln der EU-Taxonomie-Verordnung.
- KI-only: Die ESG-Zuordnung erfolgt durch die Analyse unstrukturierter Texte (Projektbeschreibung, Pressemitteilungen, externe Berichte) mittels NLP (Natural Language Processing). Das Ergebnis ist eine probabilistische Klassifizierung.
- Hybridansatz: KI extrahiert relevante Merkmale und Entitäten aus den Texten (z.B. Standort „Spanien“, Technologie „Photovoltaik“, Leistung „50 MW“). Die Ontologie klassifiziert diese extrahierten, strukturierten Daten dann auf Basis definierter ESG-Regeln (z.B. „Solarpark“ ist Unterklasse von „Erneuerbare Energien“, „Erneuerbare Energien“ erfüllt Taxonomie-Kriterium X).
Der Hybridansatz bietet hier sowohl Kontexttiefe und Effizienz durch KI als auch die Regelkonformität und Auditierbarkeit durch die Ontologie – besonders wichtig für SFDR-Meldungen oder Investorenreports.
8. Governance und Regulatorik – warum Struktur immer noch gefragt ist
Regulatorische Vorgaben wie SFDR, EU-Taxonomie, Solvency II, CRR II oder BaFin-Investmentstatistik verlangen strukturierte, nachvollziehbare Begriffszuordnungen. Freitextfelder oder rein KI-basierte Klassifizierungen genügen hier (noch) nicht den Anforderungen an Transparenz und Auditierbarkeit. Auch interne Kontrollsysteme (IKS) und Auditprozesse setzen auf stabile Begriffswelten und eine nachvollziehbare Versionierung – ein klassisches Argument für Ontologien oder zumindest strukturierte Taxonomien.
9. Fazit: Weiterbauen, abschaffen oder transformieren?
Ontologien sind weder obsolet noch allein selig machend. In dynamischen Datenumgebungen und heterogenen Fondslandschaften wirken sie manchmal träge – doch sie bleiben ein unverzichtbares Ordnungsprinzip für Compliance, Reporting und Governance.
Die Zukunft liegt vermutlich in hybriden Systemen: Ontologien liefern das semantische Gerüst, KI sorgt für Kontext, Skalierung und operative Effizienz bei der Datenverarbeitung. Asset Manager sollten Ontologieprojekte daher nicht abschreiben – sondern sie als strategisches Bindeglied zwischen Datenstrategie und KI-Roadmap neu bewerten und modernisieren.
9.1 Recherchequellen & Literatur
- EU-Kommission: SFDR- und Taxonomie-Verordnungen
- INREV Guidelines zur Datenstandardisierung
- W3C: Ontology Standards (OWL, RDF)
- ESMA MiFID II Data Dictionary
- Fachliteratur zu Wissensgraphen und Semantik im Finanzwesen
- Publikationen zu KI-Anwendungen in Asset Management